Abstract
Single-view RGB-D grasp detection remains a common choice in 6-DoF robotic grasping systems, which typically requires a depth sensor. While RGB-only 6-DoF grasp methods has been studied recently, their inaccurate geometric representation is not directly suitable for physically reliable robotic manipulation, thereby hindering reliable grasp generation. To address these limitations, we propose MG-Grasp, a novel depth-free 6-DoF grasping framework that achieves high-quality object grasping. Leveraging two-view 3D foundation model with camera intrinsic/extrinsic, our method reconstructs metric-scale and multi-view consistent dense point clouds from sparse RGB images and generates stable 6-DoF grasp. Experiments on GraspNet-1Billion dataset and real world demonstrate that MG-Grasp achieves state-of-the-art (SOTA) grasp performance among RGB-based 6-DoF grasping methods.
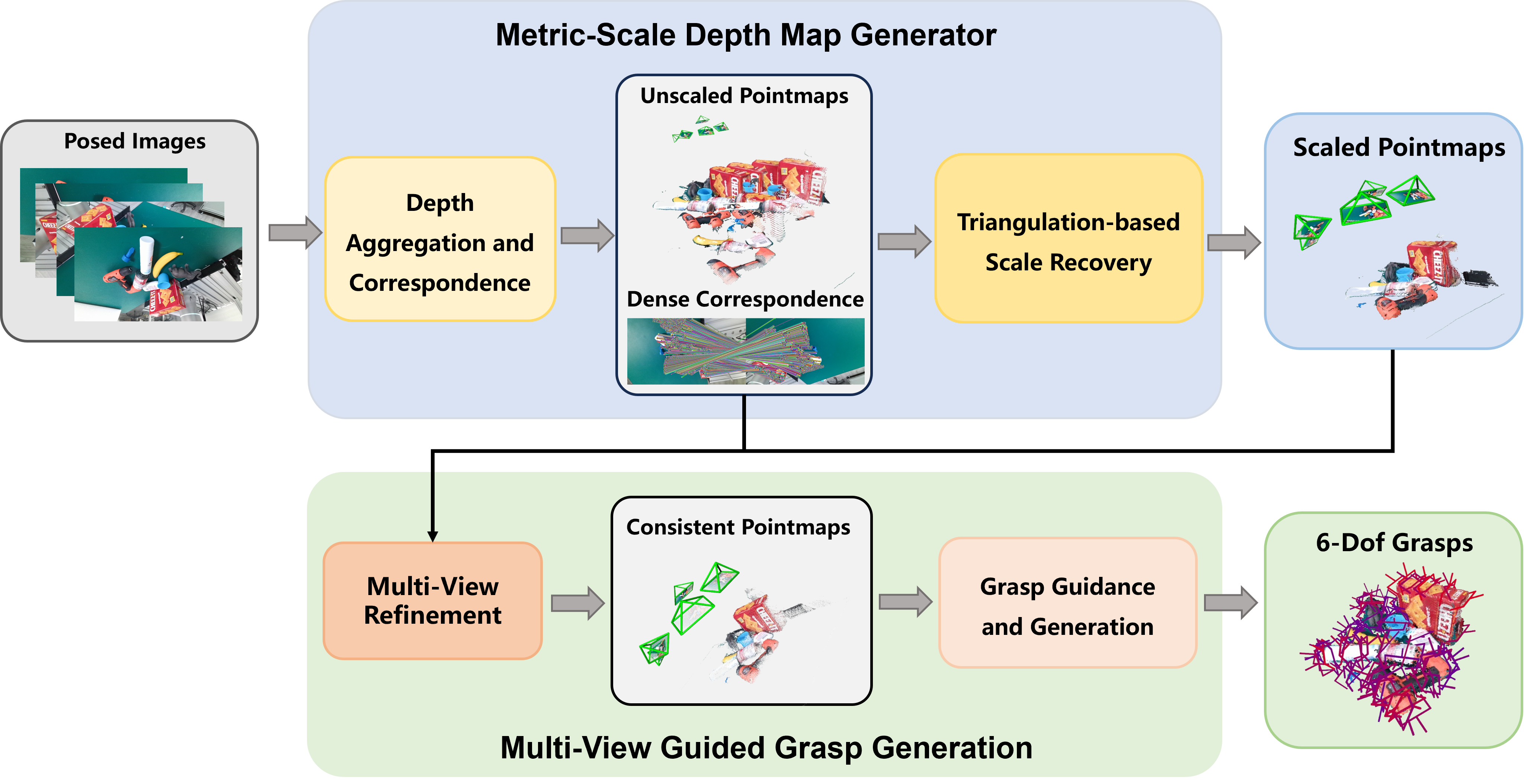
Framework Overview
Method Highlights
- Depth-free 6-DoF grasping: reliable robotic grasp generation from sparse multi-view RGB observations only.
- Triangulation-based Scale Recovery: grounds up-to-scale two-view predictions into a shared metric coordinate system.
- Two-stage Multi-View Refinement: enforces dense cross-view consistency using confidence-weighted 3D and 2D objectives.
- Grasp-oriented fusion: refined geometry is filtered and decoded into stable 6-DoF grasps with a local grasp model.
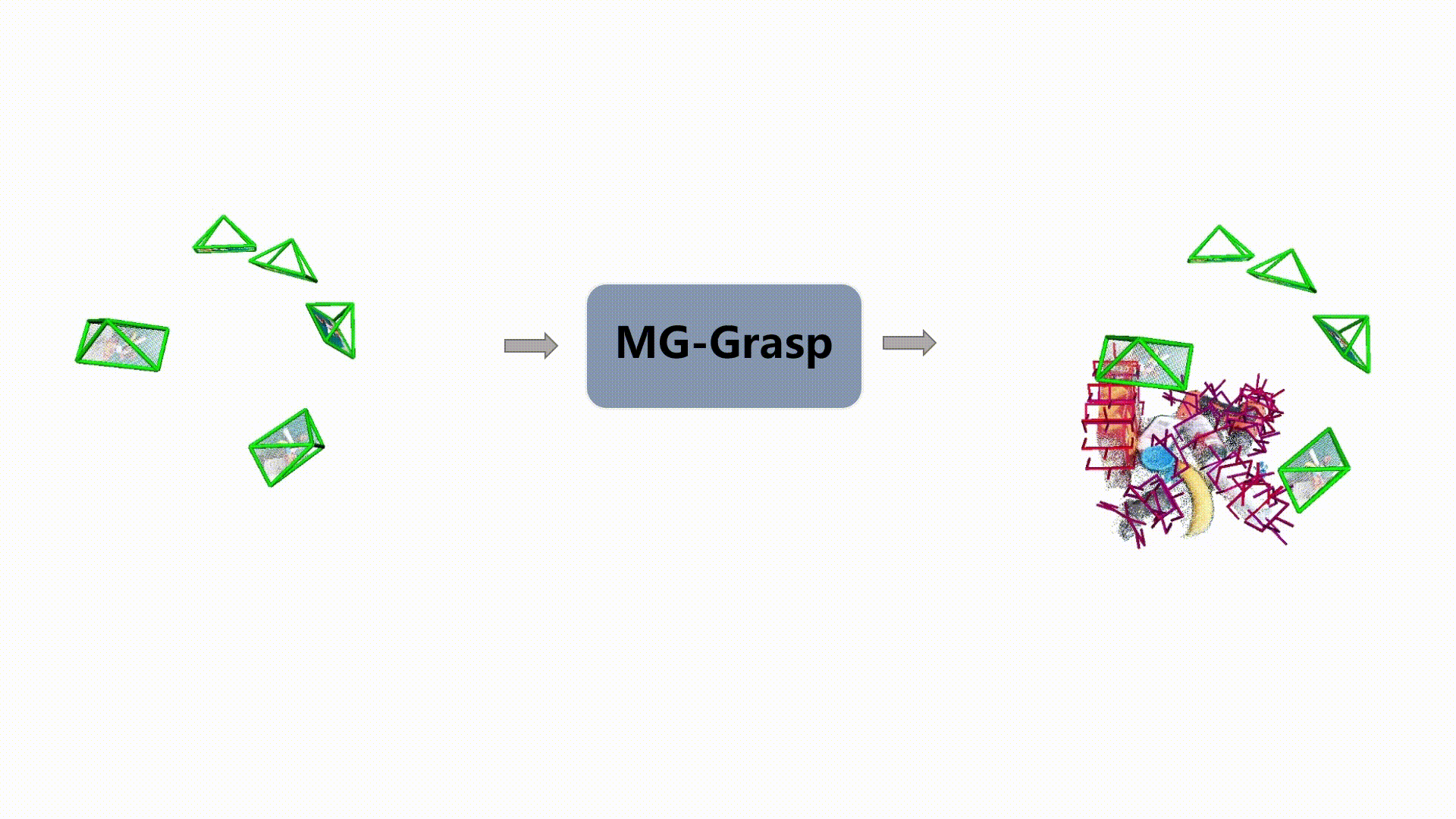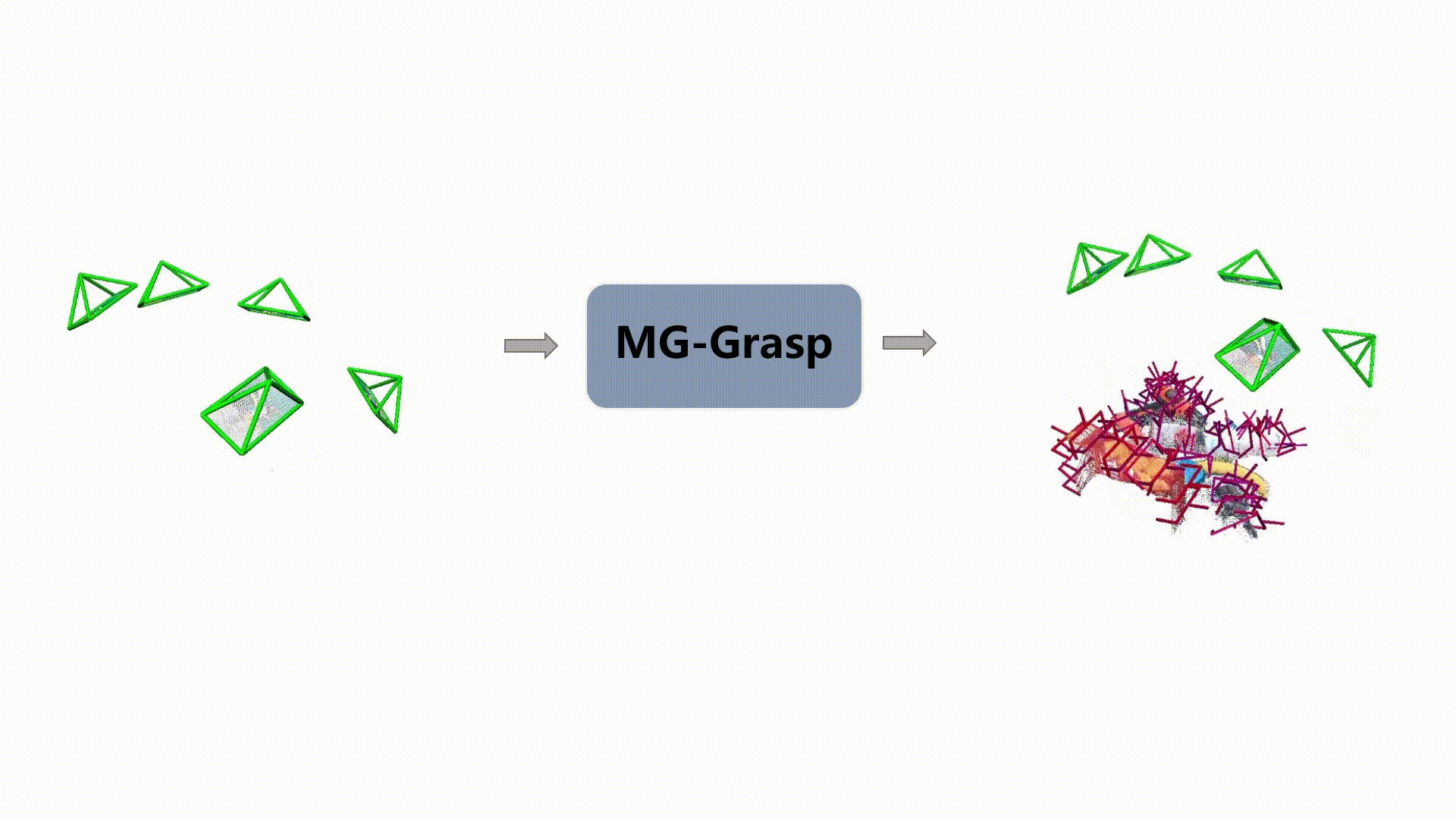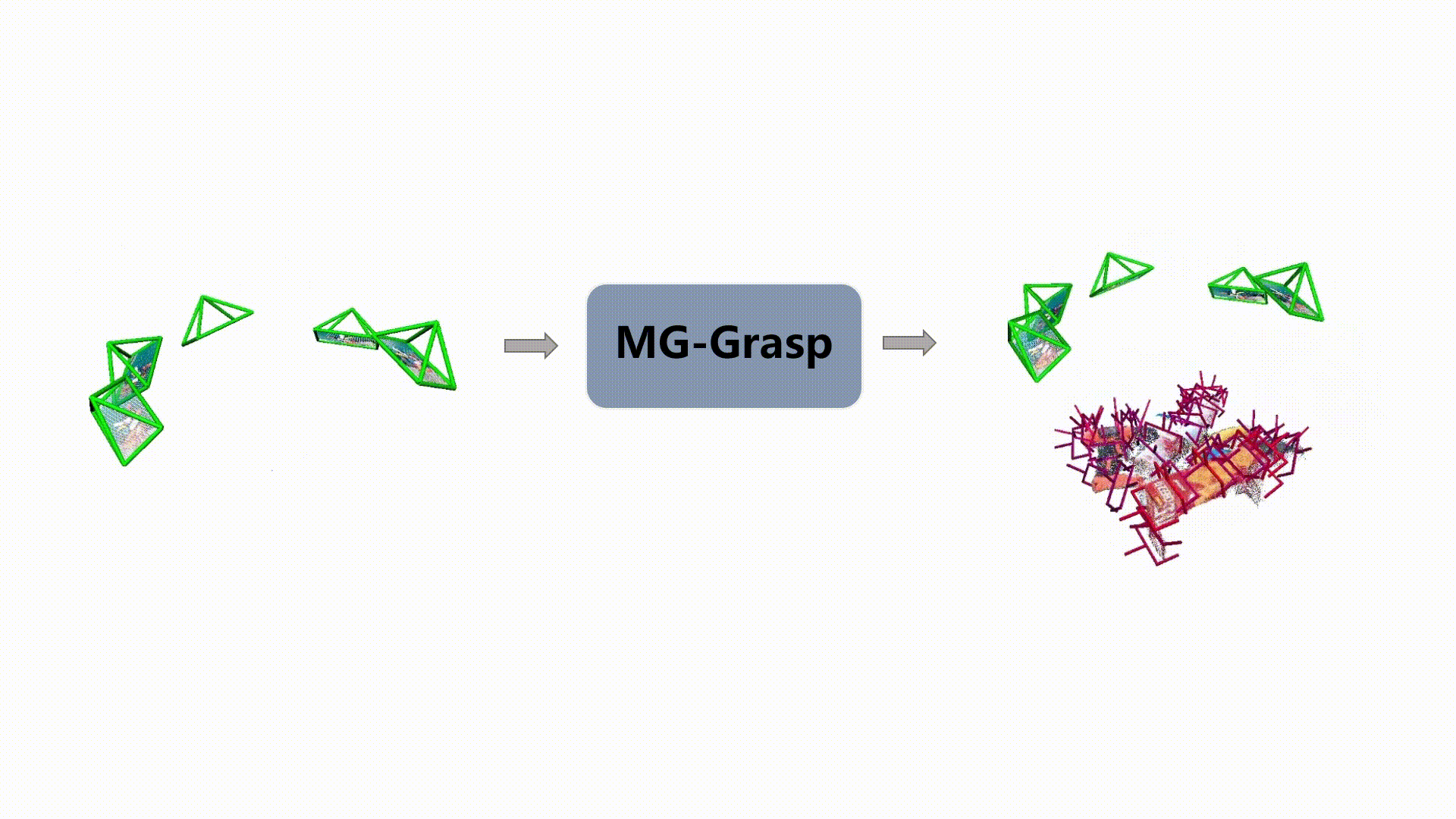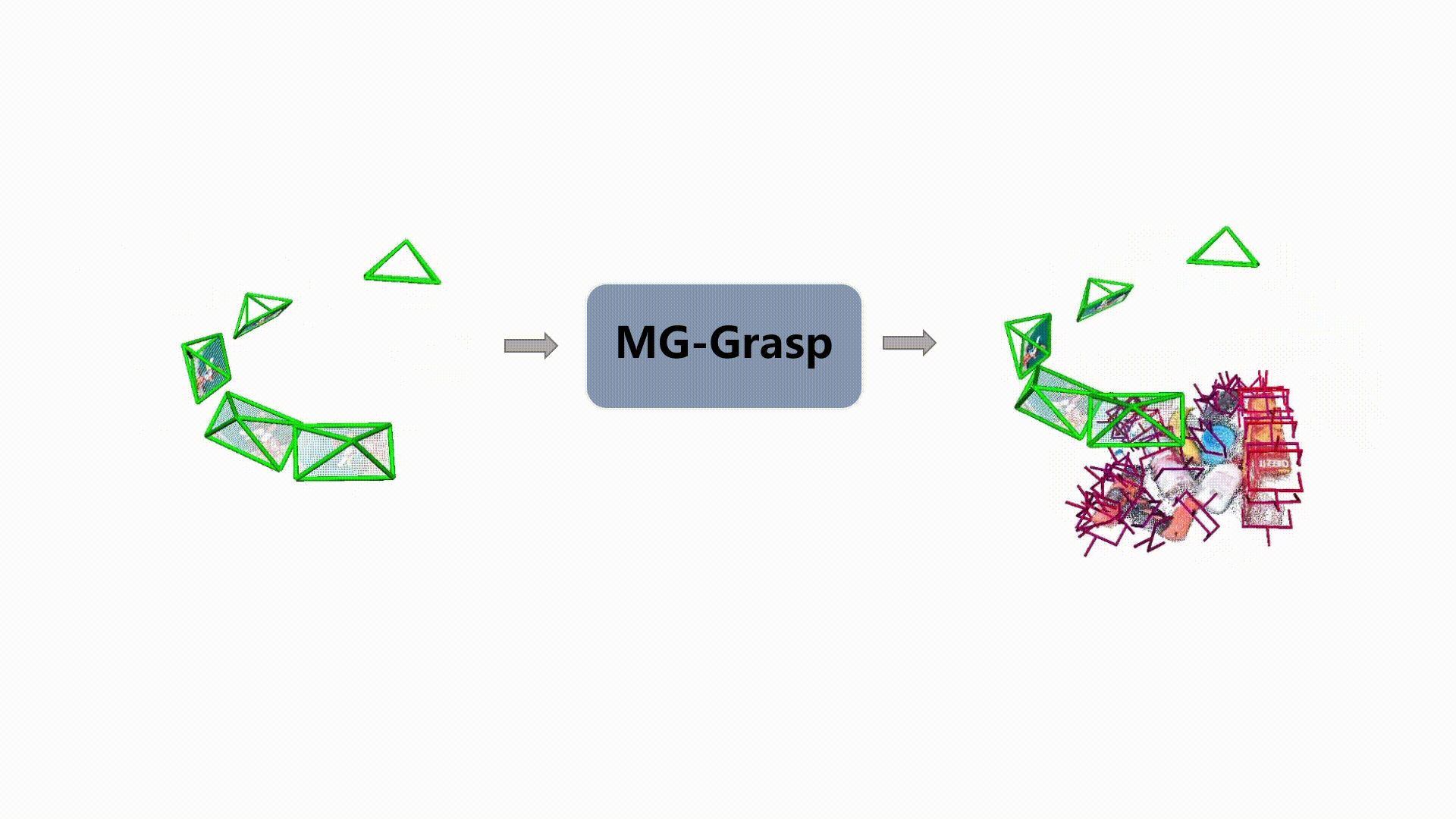
6-DoF Pose Generation
Qualitative examples of generated 6-DoF grasp poses from MG-Grasp.

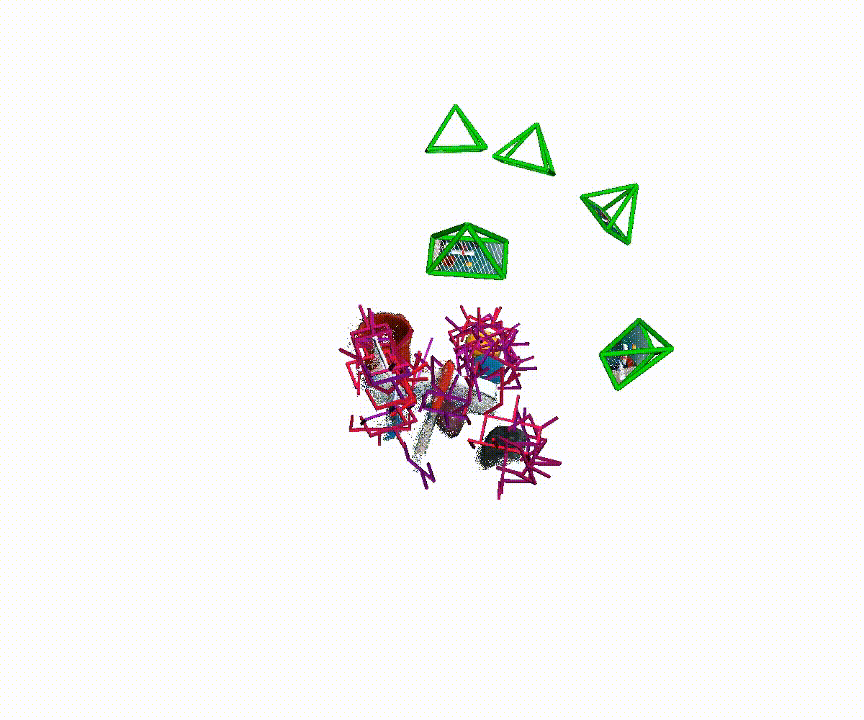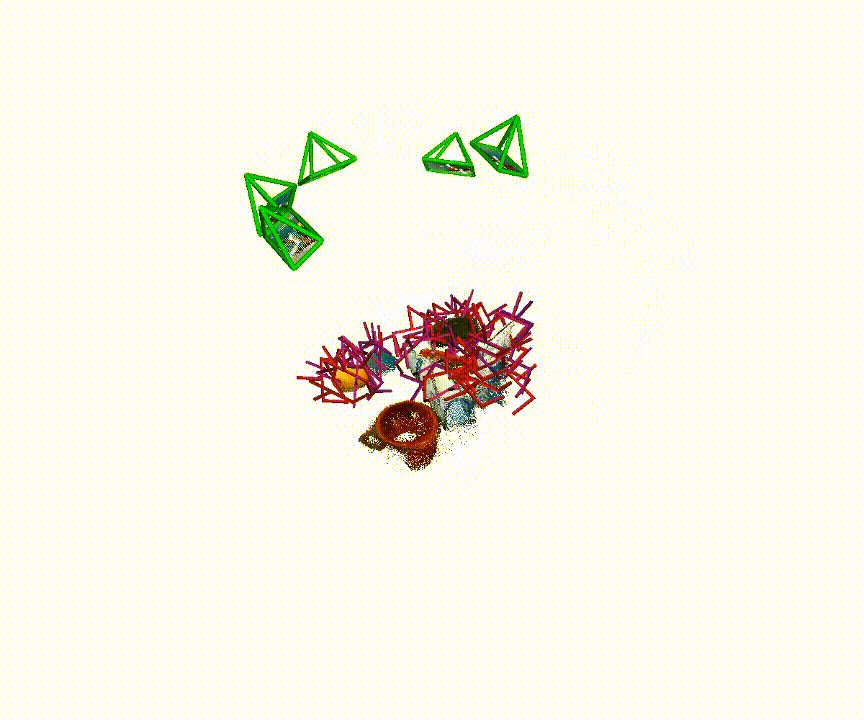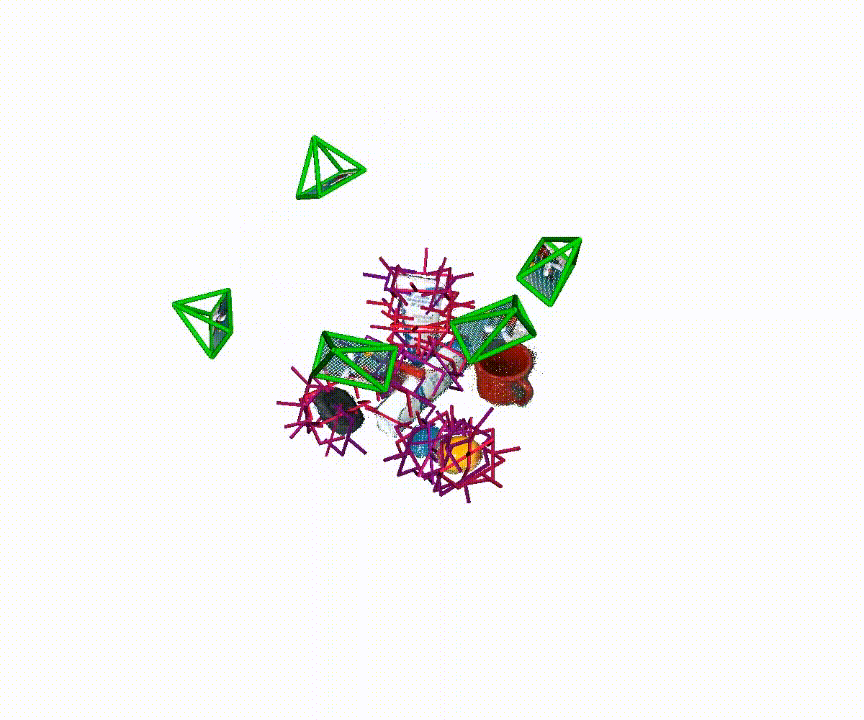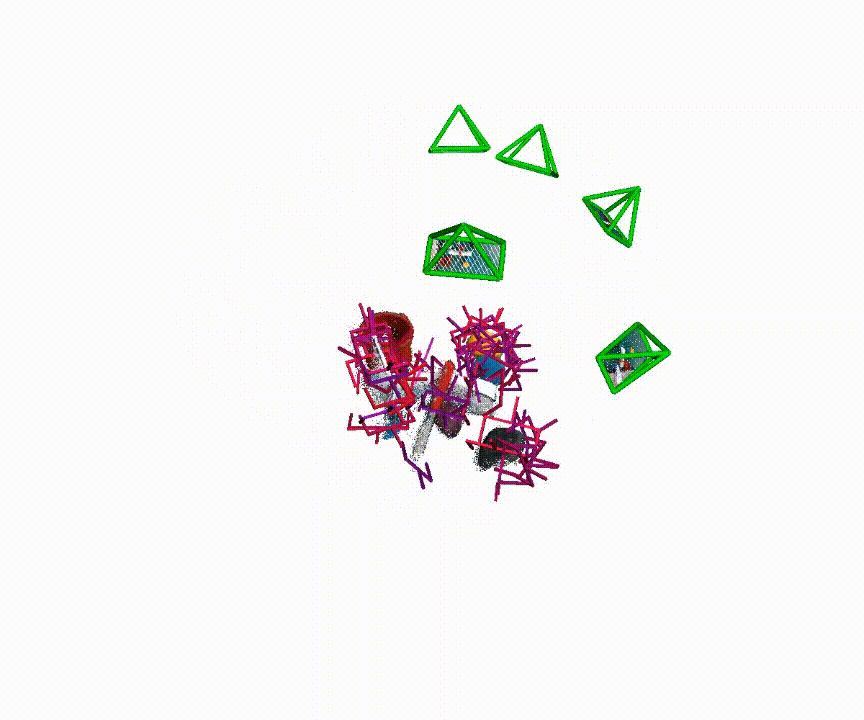

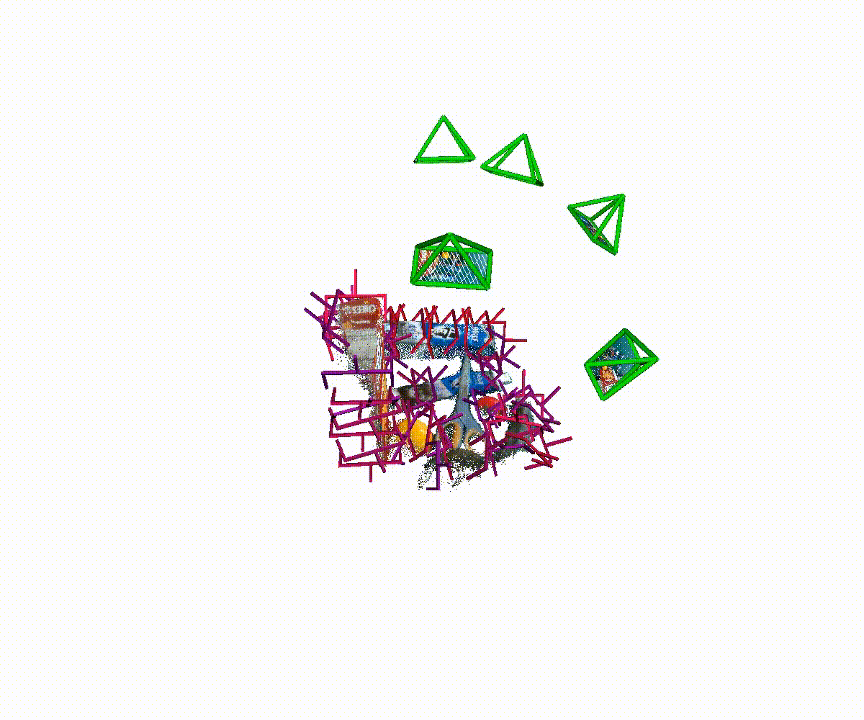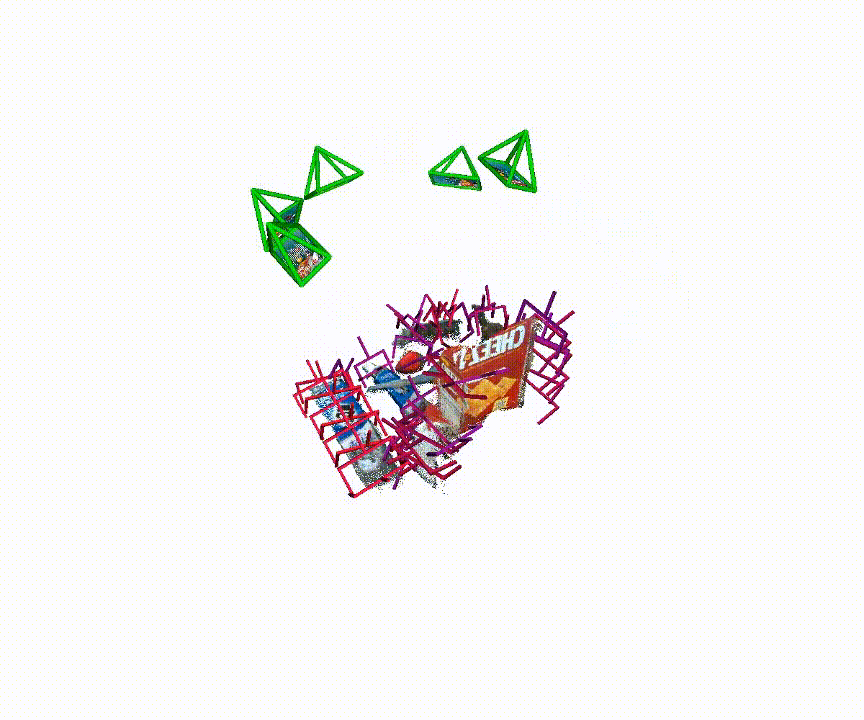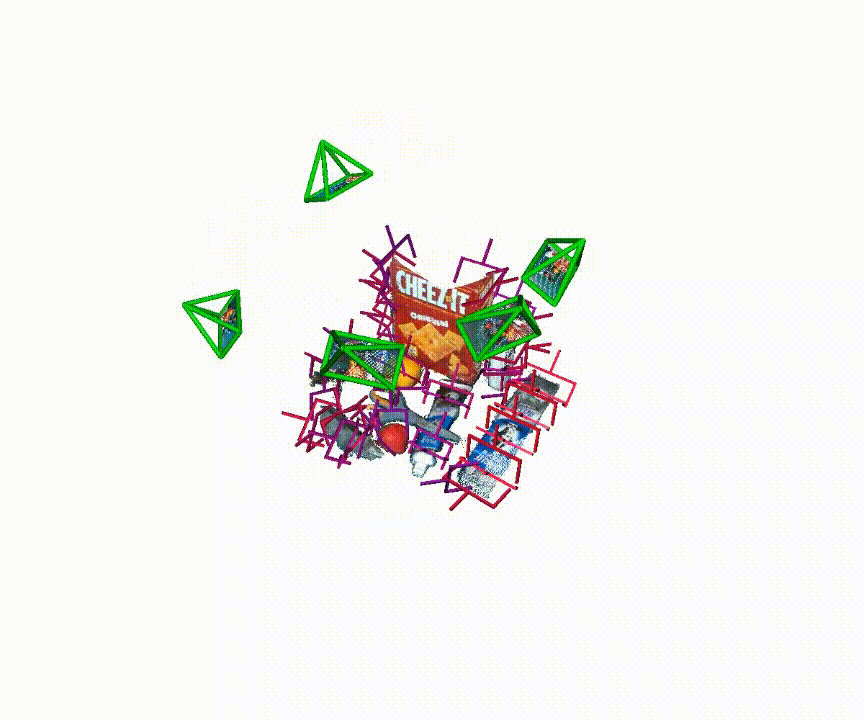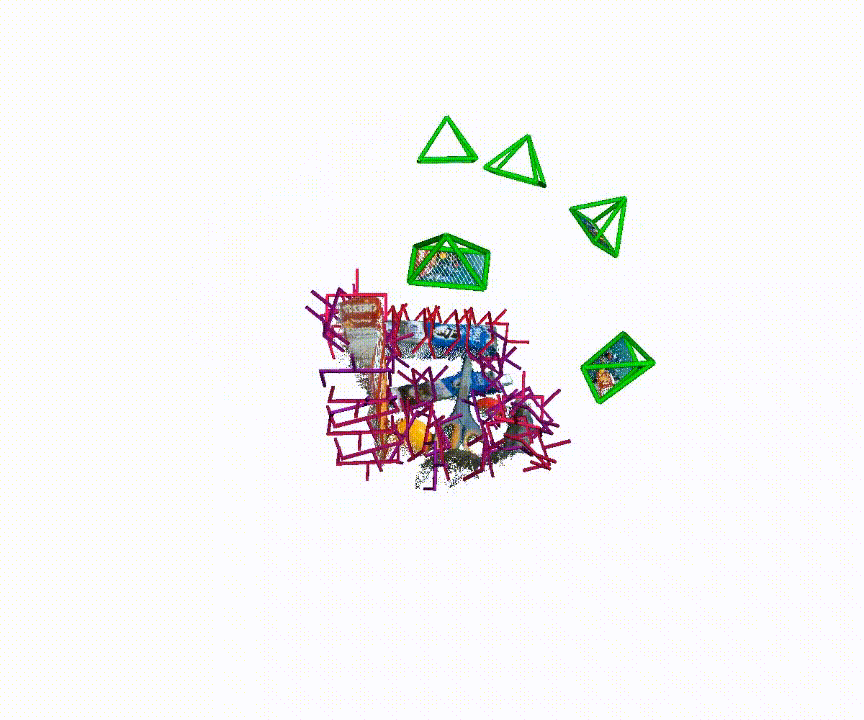
Benchmark Summary
| Method | Data | Seen | Similar | Novel | Average |
|---|---|---|---|---|---|
| PointnetGPD | RGB-D | 25.96/27.59 | 22.68/24.38 | 9.23/10.66 | 19.29/20.88 |
| GraspNet | RGB-D | 27.59/29.88 | 26.11/27.84 | 10.55/11.51 | 21.41/23.08 |
| TransGrasp | RGB-D | 39.81/35.97 | 29.32/29.71 | 13.83/11.41 | 27.65/25.70 |
| HGGD | RGB-D | 59.36/60.26 | 51.20/48.59 | 22.17/18.43 | 44.24/42.43 |
| FlexLoG | RGB-D | 72.81/69.44 | 65.21/59.01 | 30.04/23.67 | 56.02/50.67 |
| GraspNeRF | RGB | 22.49/24.61 | 14.15/17.67 | 11.08/12.86 | 15.91/18.38 |
| VG-Grasp | RGB | 59.23/54.65 | 36.34/35.13 | 10.84/11.85 | 35.47/33.88 |
| MG-Grasp (Ours) | RGB | 63.70/66.80 | 56.03/57.35 | 23.22/20.47 | 47.65/48.21 |
Real-World Robotic Evaluation
We further validate MG-Grasp on a real robotic platform in tabletop scenes using a UR5e manipulator, a Robotiq 2F-85 adaptive gripper, and a RealSense D435i camera, while only using RGB images. Different from prior single-view real-robot evaluations, MG-Grasp uses 4 sparse RGB views per scene.
- Success Rate: 35/40 = 87.5%
- Completion Rate: 35/35 = 100%
- Transparent Objects: 11/20 = 55.0% success, 11/15 = 73.3% completion
Real-World Robot Experiments
Real-robot grasping demonstrations in tabletop scenes using 4 RGB observations.

Transparent Object Grasping
MG-Grasp also generalizes to transparent-object grasping scenarios in real-world experiments.
BibTeX
@misc{wang2026mggraspmetricscalegeometric6dof,
title={MG-Grasp: Metric-Scale Geometric 6-DoF Grasping Framework with Sparse RGB Observations},
author={Kangxu Wang and Siang Chen and Chenxing Jiang and Shaojie Shen and Yixiang Dai and Guijin Wang},
year={2026},
eprint={2603.16270},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.16270},
}